
What happens when a browser loads a page? Do you know how the internals of browsers work to turn the JavaScript code you write into something usable by your computer? What happens if you want to run that same JavaScript code on your laptop instead of the browser?
We’ll explore what happens when your browser takes your JavaScript code and tries to run it with something called an engine.
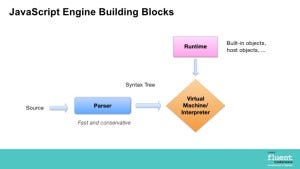
Let’s walk through the journey of pulling JavaScript code from a server to rendering its output in the browser.
Parser
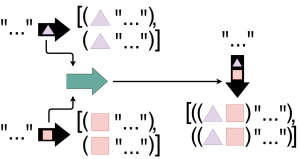
When the code is successfully fetched from the server to the client, the JavaScript engine begins right away by taking that code and feeding it to the engine’s parser. A parser looks for patterns in the code to turn it into representative objects that the machine understands. So when the parser sees things like brackets, it knows there is a block of code to evaluate. Similarly, if it sees var or let, it knows that it should allocate space for a variable and its corresponding value. The object that stores all of the parser’s translations is known as an Abstract Syntax Tree (AST).
Interpreter
Next, all of the organized objects are fed from the AST to the engine’s interpreter, which translates those objects into bytecode. The bytecode step is useful because it is the first opportunity for our machine to run our code. If the interpreter contains a virtual machine (which V8 and other JavaScript engines do have) we can immediately execute code in bytecode form, without having to translate it yet again to even more highly optimized machine code.
When would be a good time to run bytecode? As Mathias Bynens (developer advocate for Google’s V8) points out, bytecode is great for running one-off code. Sequences like Initialization and setup are great for this step because you can generate the bytecode, run it once, and never have to deal with it again. But what if you do have to keep using this code?
Compiler
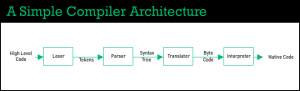
This is where the optimization step comes in. As the interpreter is translating the AST into bytecode, it’s keeping track of all of the various idiosyncrasies of your code. Are you calling the same function over and over again with numbers? Code like this is called hot code, and these types of scenarios make for a good opportunity for the engine to translate that code even further into highly-optimized machine code. This machine code can be quickly accessed and executed across multiple instruction sets. This final step is run by the engine’s compiler to send this machine code to be run directly on the CPU.
One final thing to note: all code has to be run as machine code eventually. So even though the interpreter runs bytecode while the compiler creates optimized machine code for the CPU, the interpreter’s bytecode still gets translated into machine code. The difference is that this interpreted machine code is not controlled by your engine. Bytecode on the virtual machine will be run as it sees fit, whereas optimized compiler machine code is inspected very carefully to only run the exact instruction sets required for the CPU. Hence why this optional 3rd step exists: if we see patterns for optimization, we want to control how this machine code is run. If it doesn’t require optimization, then we’re happy to let our machine code build as it feels necessary.
How does the JavaScript engine fit into this lifecycle? The JavaScript engine is the component of the browser that takes your JavaScript code, optimizes and executes it. Also known as virtual machines, JavaScript engines execute your code in an environment that is platform-independent. This means that you can run the same JavaScript code on MacOS, Windows, or Linux. It also means you can run this same code in a browser, like Chrome, or on the desktop, like with Node applications such as Electron.
Differences between engines
So why are there multiple JavaScript engines if they are trying to make JavaScript code universal? Much in the way that we have multiple browser engines (Chrome, Safari, IE, Opera, Firefox, et al.), it makes sense to tie the JavaScript engine to the browser engine. By understanding how the specific browser engine works, the JavaScript engine can effectively parse, interpret, and compile the code from the browser, while also being useful enough to be the engine driving Node applications on desktop or IoT devices as well.
The primary difference between engines lies in the choice between all of the highly-optimized compiler instructions. Each JavaScript engine, whether it’s V8 for Chrome or Chakra for IE, has maintainers that have to make careful choices about how to optimize for memory usage. Optimized compiler machine code is very memory-intensive, so it requires considerable trade-offs when trying to create ideal machine code. Because there is no “correct” answer, this opens up compiler optimizations to a variety of opinions and considerations, which leads to all of the various JavaScript engines we have available today.
Considerations across devices and environments

As we mentioned earlier, one major advantage of using a JavaScript engine is the interpreter’s virtual machine which allows developers to create platform-agnostic JavaScript code. This code can be interpreted to run on any platform, whether it’s on the browser or on the desktop.
The browser ecosystem is considerably different from the Node ecosystem. Should your JavaScript code that runs as a server be optimized differently than JavaScript code being run as a command line tool? If so, why would an engine like V8 be the same for both optimized command line code and browser code?
The biggest reason against forking is maintainability. While it would be great to create application-specific engines that are highly optimized for specific machine interactions, the difficulty becomes maintaining an ever-increasing and sparse distribution of engines that all conform to the same Ecma 262 standard. Intuitively, it would seem much easier to just update V8 when ES6 added arrow functions than to have to update V8 for Chrome, V8 for Node, and so on.
In spite of this, we still see fragmentation as a good thing, particularly for IoT devices. XS is one such example of a JavaScript engine that is specifically designed for applications that run on IoT devices. Its memory considerations are stricter than a browser-based engine like V8, allowing it to make better use of constrained devices than a typical JavaScript engine would.
Security implications
While interoperability makes JavaScript engines a desirable complement to a browser engine, one important consideration with allowing a virtual machine to freely run foreign, untrusted code is security.
One of the chief responsibilities of a JavaScript engine is to run untrusted code as securely as possible. It is common for JavaScript engine teams to work with partnering teams and organizations (like Google’s Project Zero) to catch vulnerabilities and fix them in real time; sometimes even before a TC-39 spec has made it to a public release. The ability for development teams to respond to and quickly fix security vulnerabilities has allowed the development community at large to continue to rely on JavaScript engines as the primary way of executing highly performant, highly secure code across a myriad of devices and environments.
To take an even deeper dive into the world of JavaScript engines, be sure to check out Bynens’ series on JavaScript engine fundamentals.
Originally published at softwareengineeringdaily.com on October 3, 2018.
Get the FREE UI crash course
Sign up for our newsletter and receive a free UI crash course to help you build beautiful applications without needing a design background. Just enter your email below and you'll get a download link instantly.